Abstract
Legged robots have shown notable performance in complex and natural environments. Their versatility and adaptability enable them to navigate through a wide range of terrains and scenarios, demonstrating remarkable capabilities in tasks such as exploration, search, and rescue, and even some basic forms of interaction with the environment. These capabilities make them invaluable tools in real-world scenarios where human access may be difficult and dangerous. However, despite their advanced design and impressive functionality, legged robots are not immune to mechanical problems, particularly joint damage. Joint damage can arise from a variety of factors, including the natural wear and tear of moving parts over time, external impacts from sudden collisions, and even manufacturing defects. These issues can lead to significant disruptions in the robot’s normal movement patterns and balance, which in turn can impact its ability to carry out tasks effectively. When joint damage occurs, it often results in decreased mobility, reduced stability, or loss of precise control, thereby compromising the robot’s overall performance and its ability to function in challenging environments.
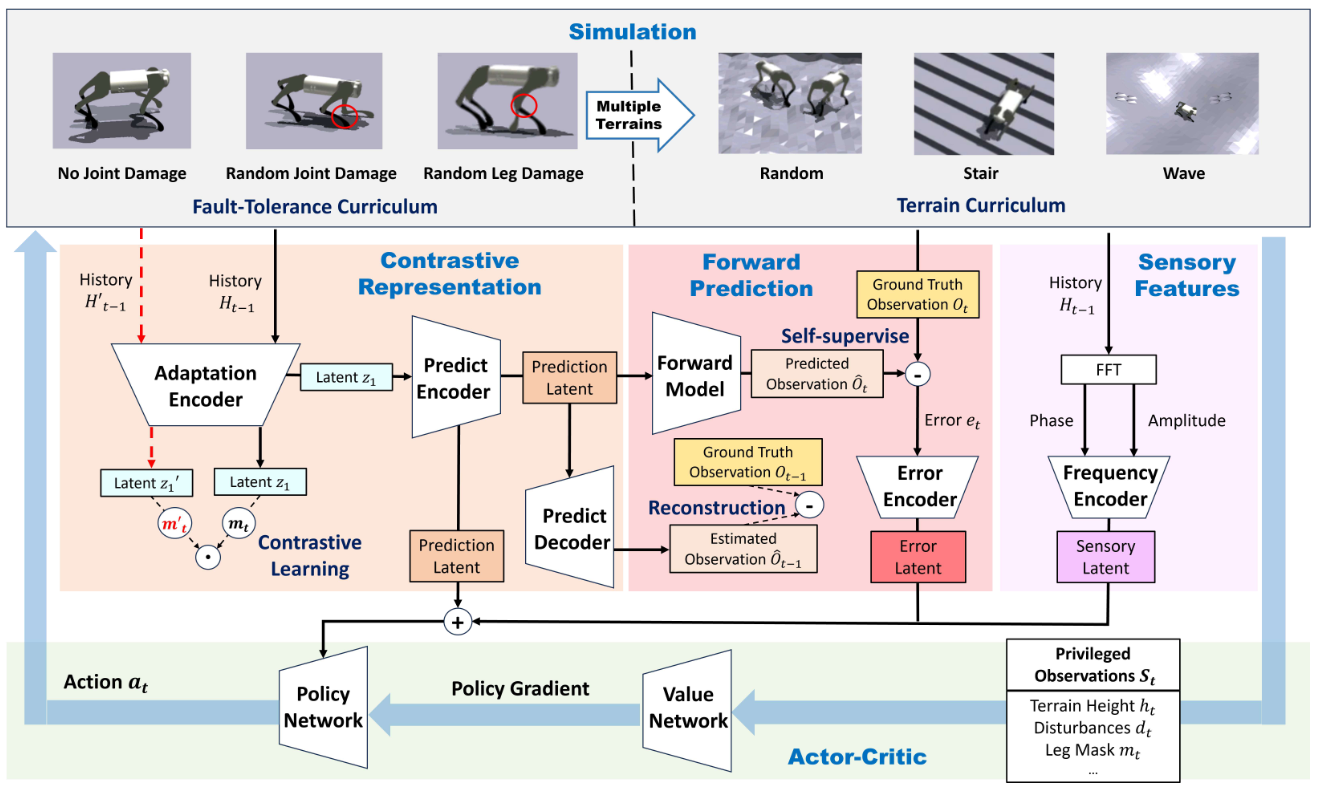
Method
This framework is designed to enhance the adaptability and fault tolerance of legged robots by mimicking biological mechanisms. Specifically, it constructs a feedforward adjustment model that includes both a comparator and a forward model, which are implemented using neural networks. These networks predict the robot's next state based on its current state and the control commands issued by the controller. The predicted state is then compared with the actual observed state, generating prediction errors. Subsequently, these errors are fed back into the controller, enabling it to adjust and refine its control signals. As a result, this iterative feedback loop allows the controller to continuously learn and adapt, significantly improving the robot's resilience to joint damage.
Fig. 1 Overview of Cerebellum-Inspired Reinforcement Learning (CeIRL) framework. By comparing the predicted result with the actual outcome, it adjusts the movement accordingly. This mechanism plays a crucial role in locomotion learning and adaptation.
Result
Deployment of the presented fault tolerance controller under various terrains and joint damages. a, Snapshots of the quadruped robot's locomotion across different terrains and under varying joint damage conditions. b, Joint torques of the right front leg when the hip joint is damaged. c, Training performance of the proposed framework without different components (CL denotes contrastive learning, PE denotes prediction error, and RJM denotes random joint mask). d, Prediction results of the healthy joint and the damaged joint. e, Gravity distribution in the $z$-direction of the robot under different joint damage conditions in the frequency domain. f,g The t-SNE comparison results between the baseline method (DreamWaq with RJM) and our method. \textbf{h}, Velocity tracking results of the robot under joint damage conditions across different terrains.

Deployment of the learning framework on the hexapod robot. a, Hexapod robot climbing stairs with joint damage (sim-to-sim validation). b,c, Snapshots of real hexapod robot experiments on flat and grass terrain. d, Torque changes of the all joints when the left and right middle thigh joints are simultaneously set to zero torque.
e, Joint position variation under zero torque damage. f, Pass rate of quadruped and hexapod robots under different terrains and joint damages. The number following the terrain type represents the difficulty of the terrain. For example, 'stairs-0.1' indicates a stair height of 0.1m.

