Abstract
Learning-based controllers show promising performances in robotic control tasks. However, they still present potential safety risks due to the difficulty in ensuring satisfaction of complex action constraints. We propose a novel action constrained reinforcement learning method, which transforms the constrained action space into its dual space and uses Dirichlet distribution policy to guarantee strict constraint satisfaction as well as stochastic exploration. We validate the proposed method in benchmark environments and in a real quadruped locomotion task. Our method outperforms other baselines with higher reward and faster inference speed. Results of the real robot experiments demonstrate the effectiveness and potential application of our method.
Method
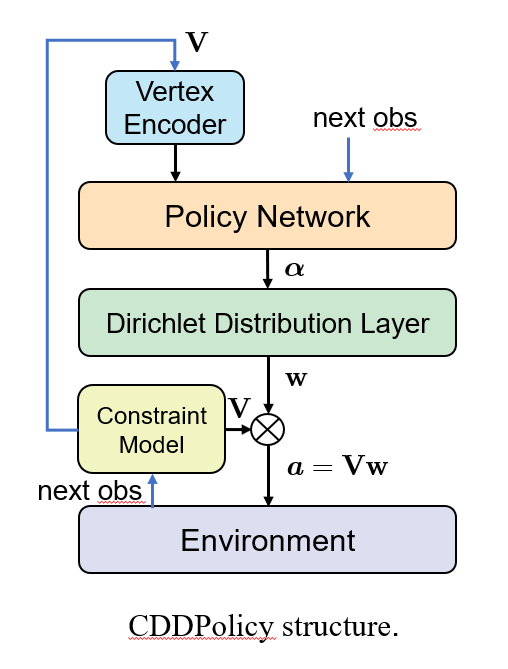
To ensure strong satisfaction to single-step output constraints, we employ a novel action parameterization method integrated into the policy architecture. We represent feasible actions as convex combinations of the vertices of the feasible domain. These vertices are dynamically computed online by the constraint model, while the neural network outputs the weights for the convex combination. Additionally, we utilize Dirichlet distribution as the policy’s output distribution in order to introduce stochastic during the exploration process.
Fig. 1 illustrates the overall framework of our method. The constraint model computes the vertex representation V of the constraint set, which is then input as augmented observations to the policy. The policy outputs weight parameters w of the convex combination of these vertices. These weights are sampled from the Dirichlet distribution layer. The final action is obtained by multiplying the vertices and weights, thereby ensuring strong satisfaction of constraints.
Result
CDDPolicy outperforms other baselines on most benchmark tasks.
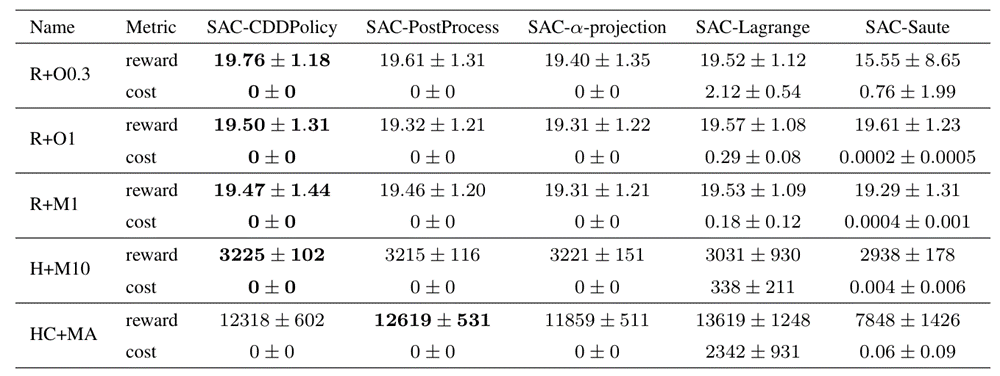
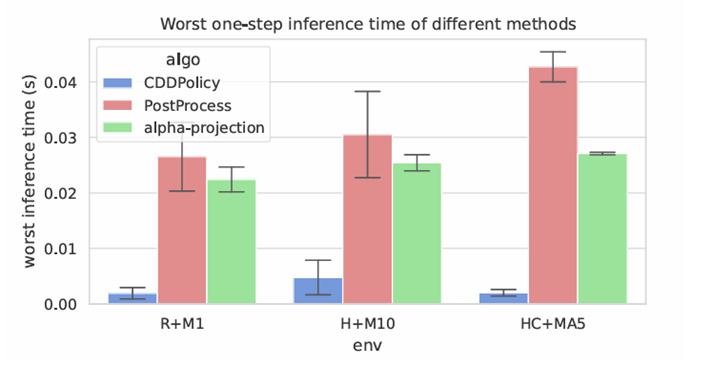
CDDPolicy exhibits a lower worst-case inference time.
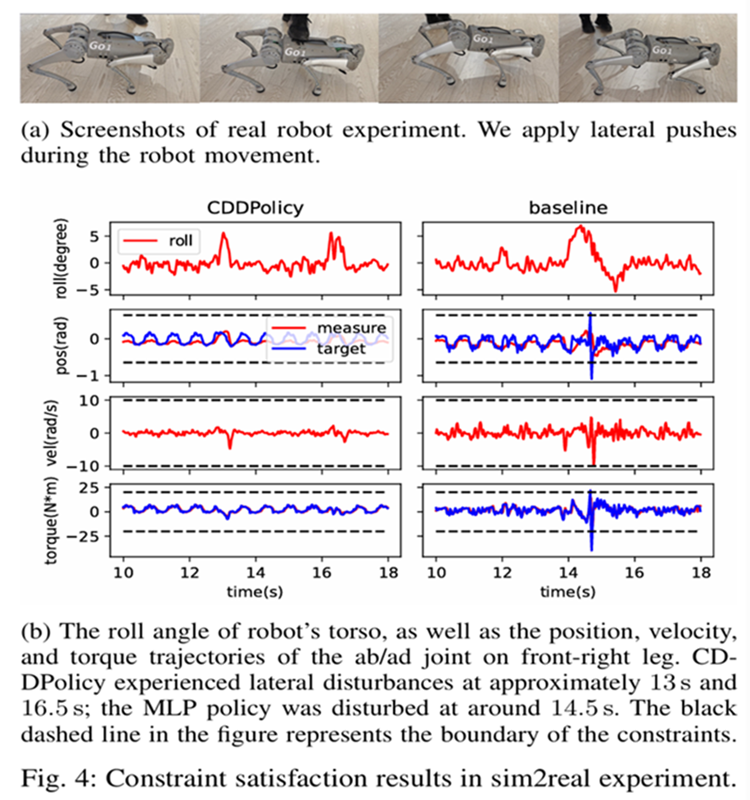
We apply our method to the locomotion task of quadruped robots with safety joint constraints.
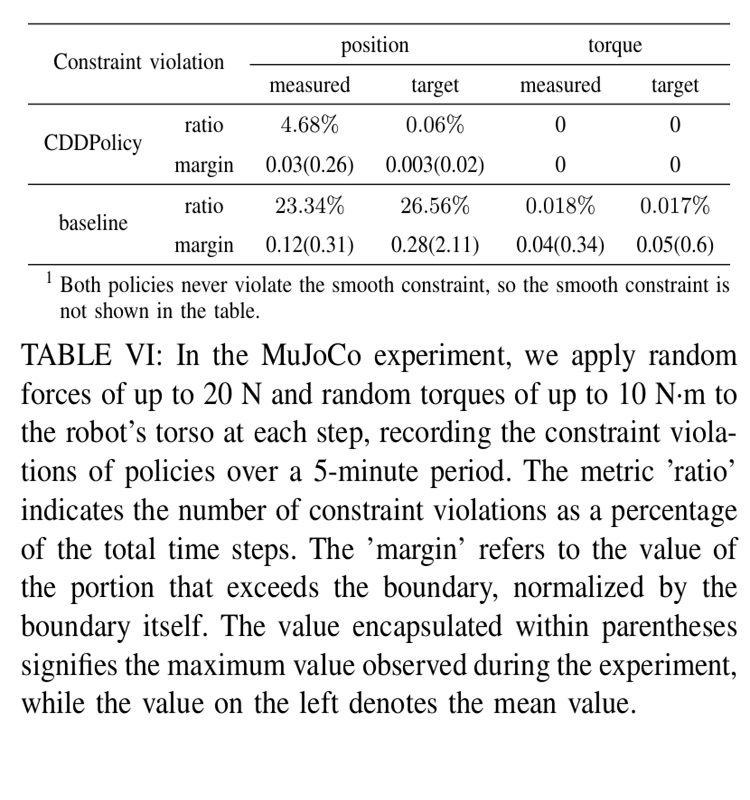
We train the CDDPolicy and the MLP policy using PPO, respectively. After a relatively short 1000 iterations, these two policies are transferred to the real robot. The experimental results show that CDDPolicy can still maintain constraint satisfaction under external disturbances and has more stable motion behavior; while the MLP policy exhibits violations of constraints and unstable behaviors.
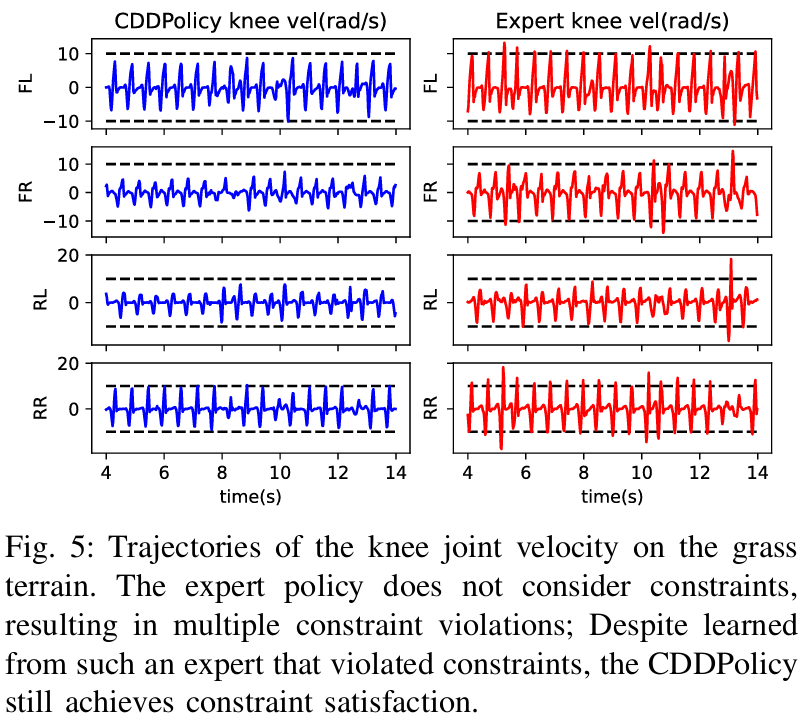
In the second experiment, we first train the CDDPolicy to imitate the unconstrained expert policy, and then train the CDDPolicy through reinforcement learning using the same reward function as the expert policy. The expert policy does not take constraints into account, resulting in many violations of constraints. Despite imitating unconstrained expert actions, CDDPolicy is still able to achieve constraint satisfaction and achieve stable motion performance similar to that of the expert.