Abstract
Deep Reinforcement Learning (DRL) has achieved significant advancements in legged robot locomotion tasks. However, neural network-based control policies suffer from action fluctuations in complex environments due to sensor noise and external disturbances, resulting in decreased locomotion performance. In this work, we propose a novel robust locomotion policy schema leveraging Multi-dimensional Gradient Normalization (MGN) to achieve policy parameterization that satisfies Lipschitz constraint at the network level, and constructs a Lipschitz Constant Network (LCN) to dynamically adjust the local Lipschitz constant of the motion policy to balance motion performance and robustness. The proposed Lipschitz Locomotion Policy (LLP) improves the smoothness of actions and is robust to observation noise and external disturbances. We validate our method in both simulation and real deployment, demonstrating that it outperforms existing methods in velocity tracking performance and the success rate of traversing complex terrain.
Method
In this work, we propose a policy network with adaptive Lipschitz constraint, utilizing the multidimensional gradient normalization method to parameterize the policy while satisfying the Lipschitz constraint. We also train a Lipschitz constant network dynamically adjusting the Lipschitz constant, balancing motion performance and robustness. Employing state-of-the-art asymmetric actor-critic architecture, we train quadruped motion policy in IsaacGym simulation and achieve zero-shot transfer to real robots for robust motion control.
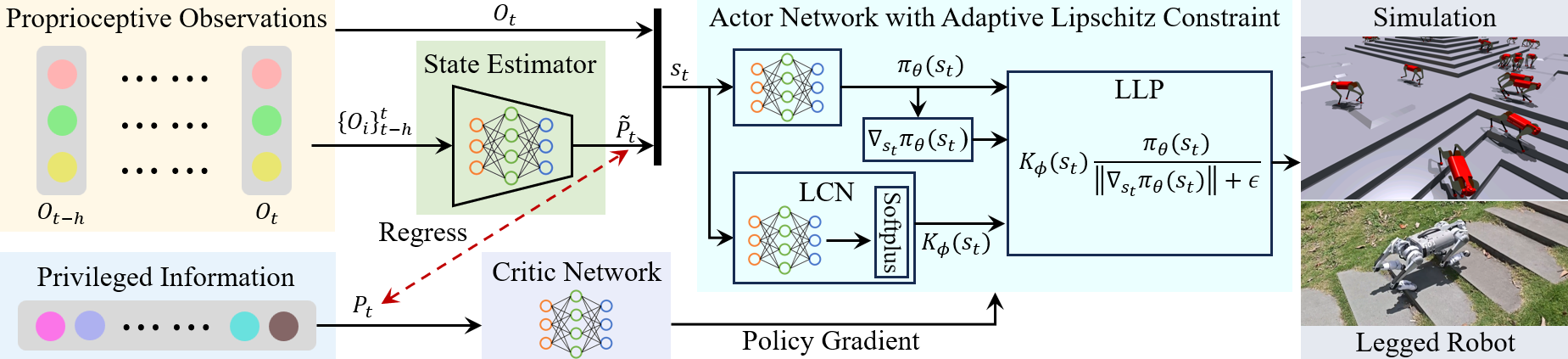
Overview of the training framework for locomotion policy with adaptive Lipschitz constraint. Using an asymmetric actor-critic architecture, the state estimator estimates privileged information given partial temporal proprioceptive observations. The LLP is constructed based on the MGN method to satisfy Lipschitz constraint, and the LCN is designed to adaptively adjust the local Lipschitz constant of the LLP.
Experiment
We conducted extensive experiments on the Unitree Go1 quadruped robot, demonstrating that our proposed method generates smoother motion sequences compared to baseline methods, significantly improving the robustness of the control policy.


Our method significantly improves the velocity tracking performance, and the Lipschitz constant network dynamically adjusts the Lipschitz constant in different environments.


The Lipschitz policy exhibited lower action fluctuation ratio and higher velocity tracking accuracy, and exhibits lower joint power and improved energy efficiency.


In the experiment of resisting external disturbances, our policy results in smaller joint position fluctuations and no significant changes in the robot's motion trajectory.

Furthermore, we observed that the robot will not experience huge motion fluctuations when the task instructions cannot be completed due to factors such as falling, and it can continue to maintain its mobility after manually recovering its body.

We further demonstrated the locomotion performance of the Lipschitz policy in various challenging environments, including soft sandy terrain, slippery pebble surfaces, and deformable sponge pads. Our method achieved traversability on common unstructured terrains. Benefiting from the smooth action and disturbance recovery capabilities enabled by Lipschitz constraint, the robot showed particular advantages in terrains where the foot is prone to slip.

