Abstract
Reinforcement Learning (RL) has achieved remarkable success in various continuous control tasks, such as robot manipulation and locomotion.
Different to mainstream RL which makes decisions at individual steps, recent studies have incorporated action repetition into RL, achieving enhanced action persistence with improved sample efficiency and superior performance.
However, existing methods treat all action dimensions as a whole during repetition, ignoring variations among them.
This constraint leads to inflexibility in decisions, which reduces policy agility with inferior effectiveness.
In this work, we propose a novel repetition framework called SDAR, which implements Spatially Decoupled Action Repetition through performing closed-loop act-or-repeat selection for each action dimension individually.
SDAR achieves more flexible repetition strategies, leading to an improved balance between action persistence and diversity.
Compared to existing repetition frameworks, SDAR is more sample-efficient with higher policy performance and reduced action fluctuation.
Experiments are conducted on various continuous control scenarios,
demonstrating the effectiveness and necessity of spatially decoupled repetition design proposed in this work.
Method
The decision process of SDAR is composed of two stages.
(1) Selection: choose which action dimensions to change previous decisions utilizing the selection policy \(\beta\).
(2) Action: generate new actions for action dimensions that choose act in the previous stage utilizing action policy \(\pi\).
Both two stages are described as follows.

We propose to optimize the policy \(\beta\) and \(\pi\) through maximizing the objective \(J(\theta^\beta, \theta^\pi)\) formulated as follows. The policy \(\pi\) can be optimized utilizing the following objective immediately.

Following the objective, we can optimize the selection policy \(\beta\) utilizing importance sampling.

In this work, we conduct exploration based on entropy formulated as follows.

Experiment
SDAR can improve training efficiency with higher action persistence. The following figures are the learning curves of SDAR and existing methods.

The following is the AUC value of our method and existing methods.

The APR (Action persistence Rate) and AFR (Action fluctuation Rate) are described as follows. As shown in the figures, our method achieves higher action persistence with lower action fluctuation.

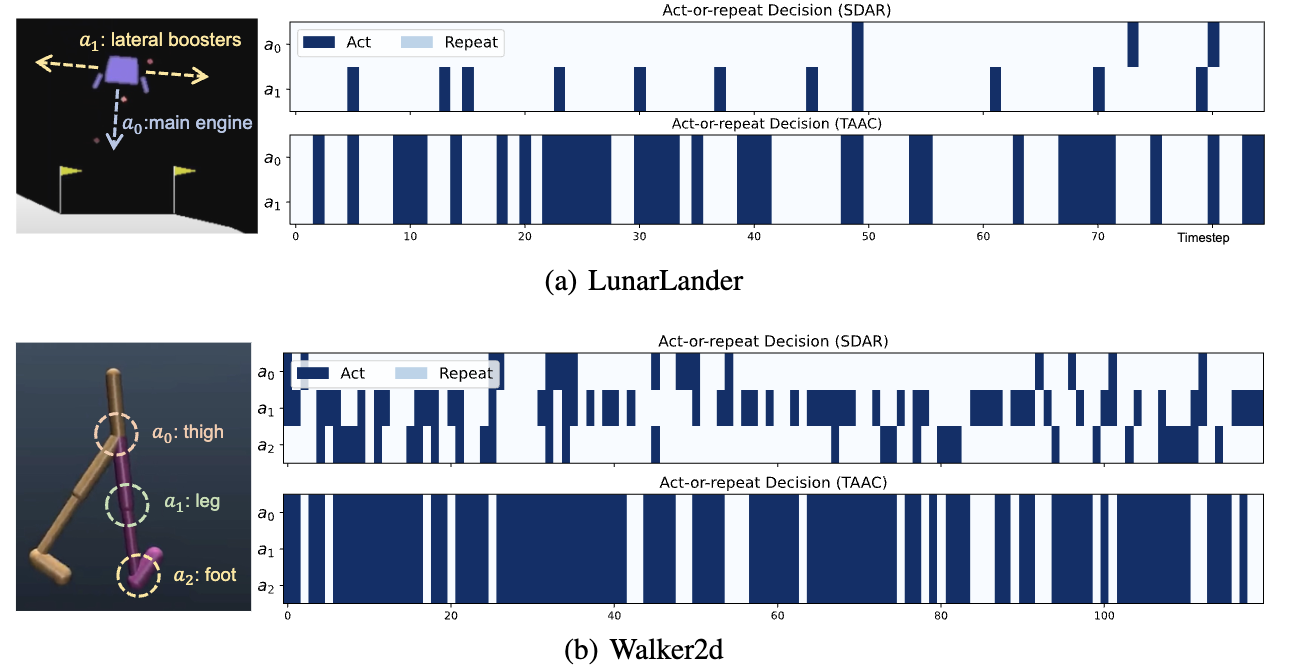
The following is the visualization of our methods and TAAC (Temporally Abstracted Actor-Critic), where our method can repeat actions of each dimension in a spatially decoupled manner.